

提到 AI 时期的最大赢家,差友们的第一响应,确定是英伟达吧?
毕竟老黄这两年靠着给 AI 厂商"卖铲子",营收和市值都"遥遥跳跃"。而这一切,都获利于 20 年前老黄据理力求,坚抓 CUDA 生态——这一把,真让他赌对了。

但你可能念念不到,还有一家公司,左手拿着性颖悟不外英伟达的显卡,右手攥着 "过时" 的 4nm 工艺,果然也在 AI 竞争里赚得盆满钵满。
而它就是——A M D!
等会,这是怎样作念到的?
前段时辰,托尼受邀参加了AMD的AI开发者大会,总结后,我对这个问题有了一些谜底。

不外这事儿嘛。。。得从十多年前苏妈靠锐龙翻身那会儿提及。
锐龙出身之前,AMD 的处理器一直活在 "i3 默秒全" 的暗影里。

直到 Zen 架构横空出世——在 "硅仙东谈主" 吉姆·凯勒的指导下,初代锐龙 IPC 性能实打实晋升了 52%,8 核 16 线程的规格,更是在阿谁 4 核称王的年代震荡全场,也拉开了芯片厂之间 "核斗争" 的序幕。

到了 2020 年的 Zen 3系列,AMD 终于一雪前耻:单核、多核性能双双干翻了英特尔同期旗舰。
而 AMD 的这场到手,也逐渐从耗尽阛阓彭胀到数据中心 B 端。说到数据中心,好多东谈主咫尺的第一响应,应该是老黄和他的 GPU 的天下。
但其实,从早期造谣机、云劳动,到如今的 AI,都离不开 CPU 的和洽转机。
所谓数据中心,其实就是一个超等物流中心,骨子是百万级的 "小快递" 同期配送。

即使单核 CPU 再快,濒临百万小件,那亦然分身乏术;而多核 CPU,就像雇了一支巨大的“司机车队”同期动身,还能通过“拼车”(造谣化)劳动更多客户,把效用拉满。
也就是说,到了数据中心这边,别管这那的,我就要阿谁核多的超大杯。
尤其是咫尺 AI 智能体兴起,用具调用、任务编排,还得靠 CPU 来干活。以至于前段时辰的 GTC ( GPU 时刻大会 )上,老黄也掏出属于英伟达的 CPU 来。

可这事儿呢,反倒是 AMD 的老本行了。在锐龙处理器解说了 Zen 架构的实力之后,AMD 的下一步,就是剑指数据中心。
十年前,数据中心的 x86 处理器,照旧英特尔的一言堂:2016 年至强 Broadwell 最高 24 核,2017 年至强 Skylake-SP 最高 28 核。
可就在同庚,AMD 运行爆种,掏出了 32 核的初代 EPYC 处理器。
而在接下来的十年里,AMD 把 EPYC 的中枢数一谈堆到了 256 核 512 线程!英特尔也被迫跟进,作念出了 128 个大核、288 个小核的居品……
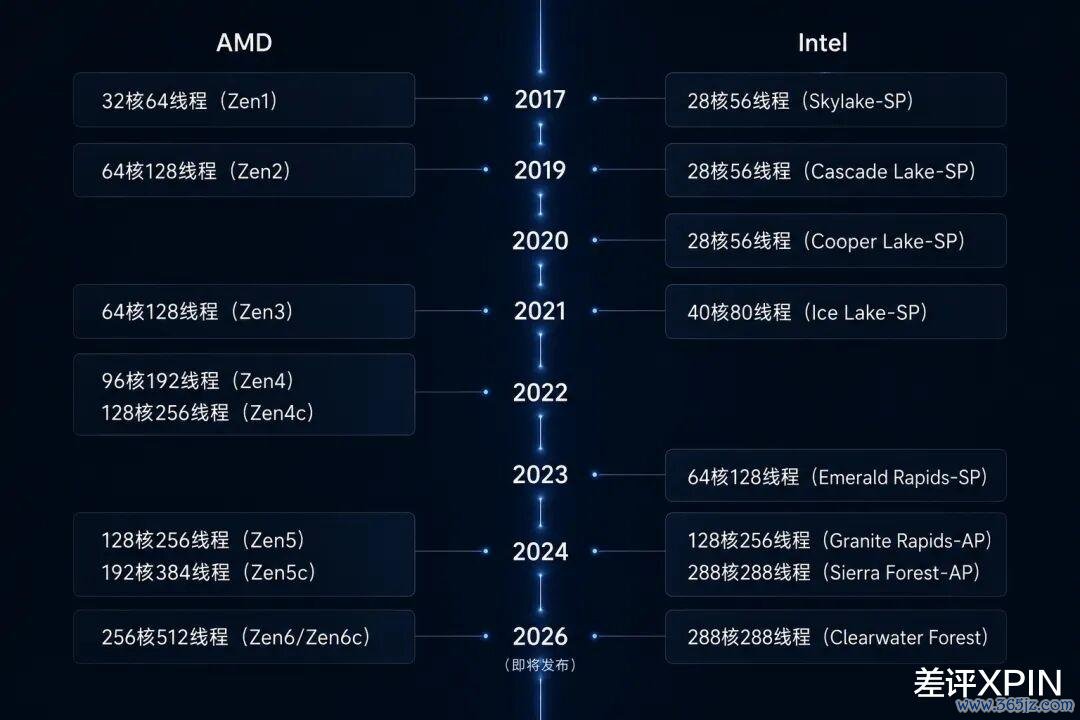
谁说英特尔不会堆中枢?这不是挺会的嘛。
是以一又友们,不是英特尔短暂有了良心,开云体育官方网站 - KAIYUN仅仅因为苏妈来过。。。
天然,光靠"低廉大碗"给家东谈主们谋福利还不够,AMD 还祭出了杀手锏——
3D V-Cache。
所谓 3D V-Cache,指的是在CPU上加一块大容量缓存。像是最早的 5800X3D,把 L3 缓存加到了 96M,对比无为版翻了 3 倍。
缓存大,关于打游戏来说,意味着帧数更高、更相识。

但缓存大可不单对游戏有效,在数据中心通常能大杀四方。非论是需要超低延长的金融交游,照旧仿真策画、有限元分析这类重策画任务,都能靠 3D V-Cache 赢得夸张的性能晋升。
就拿 EPYC 9684X 来说,96 中枢塞了足足 1152MB 三级缓存,比较竞品(至强 8490H)的上风简直达到了 3 倍。
这些功能特色方面的插足,让 AMD 在本年透顶收到了陈述。事到如今,哪个数据中心会不可爱 AMD 的 EPYC 处理器呢?
这种可爱,在阛阓份额上就体现得荒谬果真:2019 年之前,Intel 在数据中心的份额一度高达 97%;可跟着 EPYC 的崛起,这个数字在 2025 年降到了 70% 傍边。
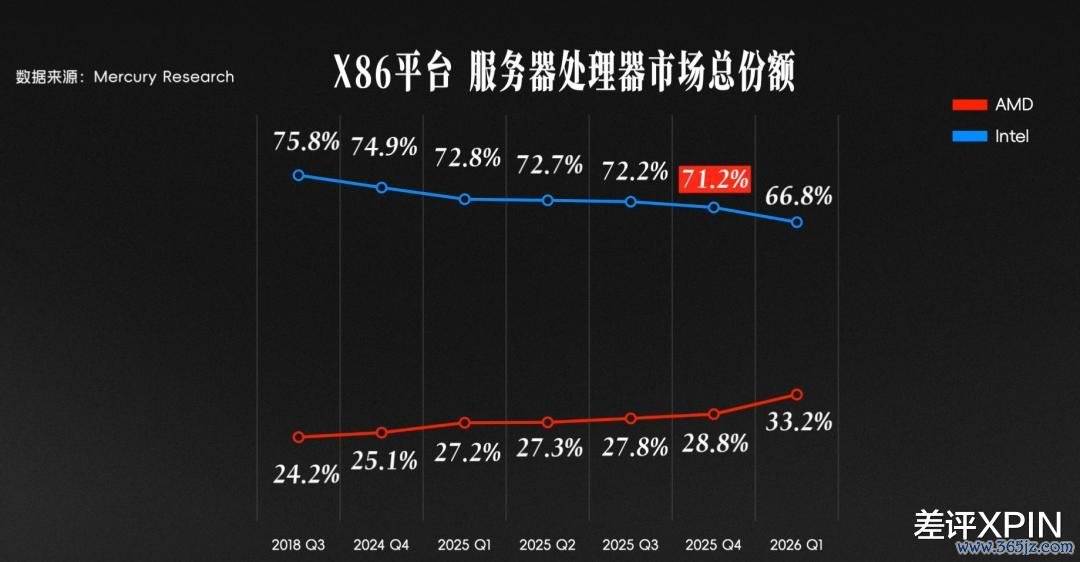
换句话说,AMD 只用了短短 6 年,就从零拿下了 30% 的阛阓份额。
看来真香定律,在数据中心这亦然能斥地的。。。

靠着向数据中心卖 CPU,AMD 再也不会像一经一样风雨涟漪,大厦将倾了。
天然了,人人也都知谈,AMD 除了 CPU,也作念显卡交易的,金花棋牌娱乐app中国官方版下载商酌词 AMD 的显卡 —— 也就是 GPU 业务,这两年过的则是。。。

其实在 2018 年之前,AMD 照旧能跟英伟达掰掰手腕的。2006 年收购的 ATi(也就是如今 AMD 的图形部门),阛阓推崇一直透着一股 "神鬼二相性":神的时候王牌对王牌,旗舰卡致使能小胜英伟达;鬼的时候呢,旗舰卡只可强迫和老黄的中端卡过过招。
可升沉点,在于老黄的神之一手:2018年,老黄运行在耗尽级 GPU 当中集成 RT Core 和 Tensor Core,况兼同步推出了晴明跟踪和 DLSS 超分时刻,如今这两项时刻,每个臭打游戏的差友,应该都不会生疏。

可恰是这两项颠覆传统光栅化渲染的时刻,让 AMD 一下子堕入了被迫:在这之后,两年后的 6000 系、四年后的 7000 系显卡,都没能拿出像样的光追和超分支柱。
直到 2025 年 9000 系显卡的发布,AMD 才算有了可以的光追推崇。而 A 卡的超分超帧时刻——FSR,早期更是用传统算法乱来。FSR 能用,但成果跟 N 卡的 DLSS 差着一截。通常,直到跟着 9000 系一同推出的 FSR4,才是实在基于 AI 的超分时刻,能和 DLSS 在画面推崇上掰掰手腕了。

换句话说,AMD 在图形时刻方面,花了 7 年时辰才追上老黄的布局。
到了劳动器端,剧情就更是人人闇练的滋味了:对 AI 支柱最佳、坐拥 CUDA 生态的 N 卡平直卖爆。AMD 这边如实没老黄那么有前瞻性,对标 CUDA 的 ROCm 直到 2016 年才出现,各种算法的支柱和优化功底,也没 CUDA 那么深厚。
总结下来就是:非论是光追、超分超帧,照旧大模子时期的软硬件支柱,又不详是硬件性能,AMD 的 GPU 如实不是英伟达的敌手。
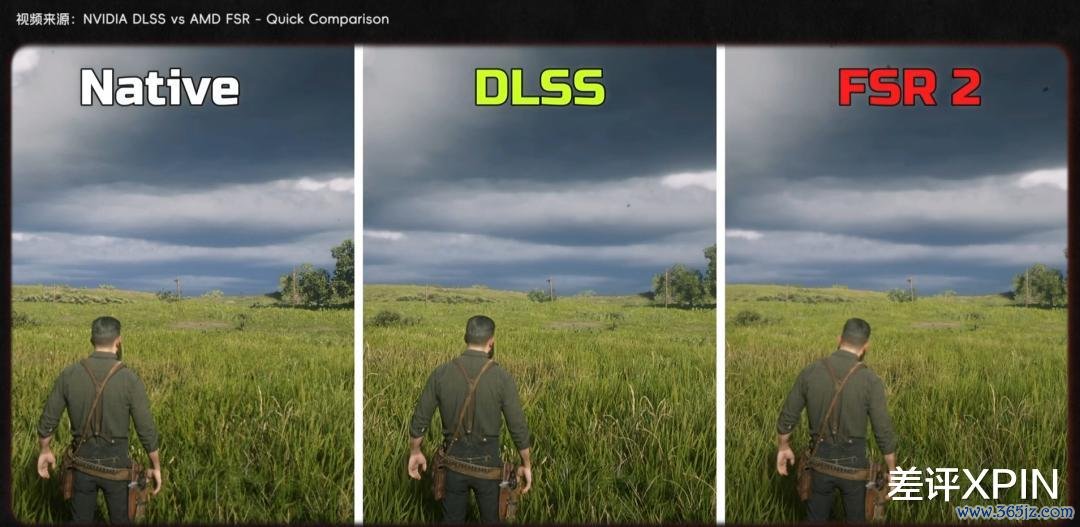
也正因如斯,很长一段时辰里,AMD 的 GPU 都是靠"性价比"这一招,吃着老黄看不上的订单。
而 AMD 保管性价比上风的圭臬其实挺浅显:又不是什么芯片都得用 2nm 先进制程,更低廉的 4nm,致使 5nm 工艺其实也够用了嘛。
资本更低,卖的天然也可以更低廉。
而倒有点“无心插柳”的嗅觉:跟着智能体引爆了阛阓对 CPU 和 GPU 的搀和需求,AMD 随机是左口袋 CPU、右口袋 GPU,都能掏出东西来。

既然双方都能自研,那就可以整点不一样的花活了。于是,AMD 尝试偷师苹果,把更大领域的 CPU 和 GPU 都塞进统一块芯片,再把内存也整合进去。
AI Max+ 395 应时而生。这颗 U 在一颗芯片里,塞入了 16 核 CPU 和 40CU 的 “核显”,性能堪比独显的同期,又可以分享系统内存,用超大内存平直跑大模子。
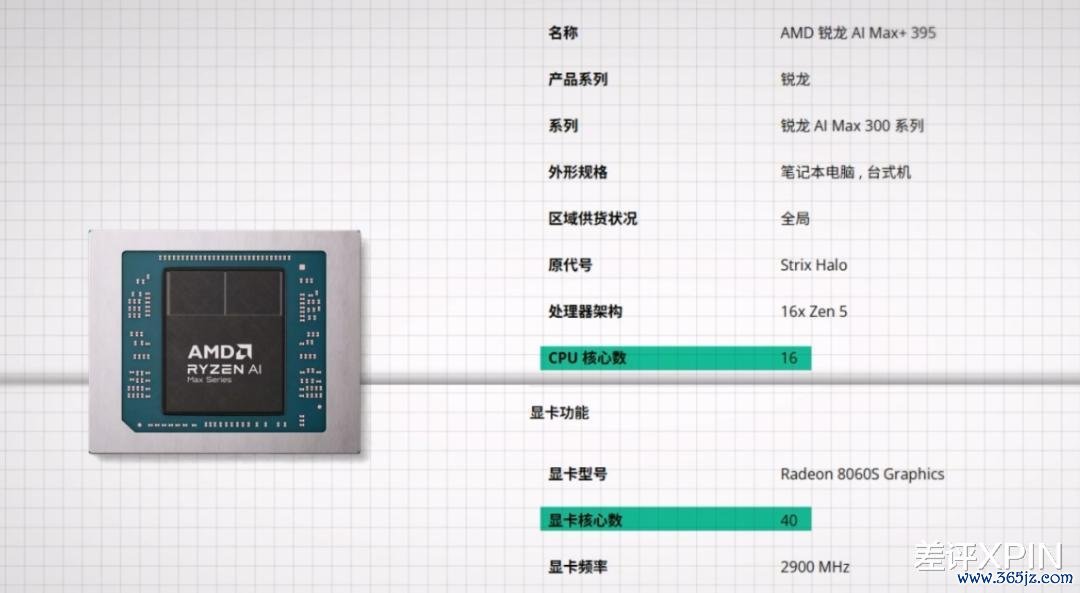
一经这个活只好苹果颖悟,可一台大内存的 Mac Studio 动辄三五万,而一台 395 的小主机只消一万多。天然依旧未低廉,但关于那些重度使用大模子、同期又有隐自费心的小伙伴来说,这个价格其实……挺合算的。
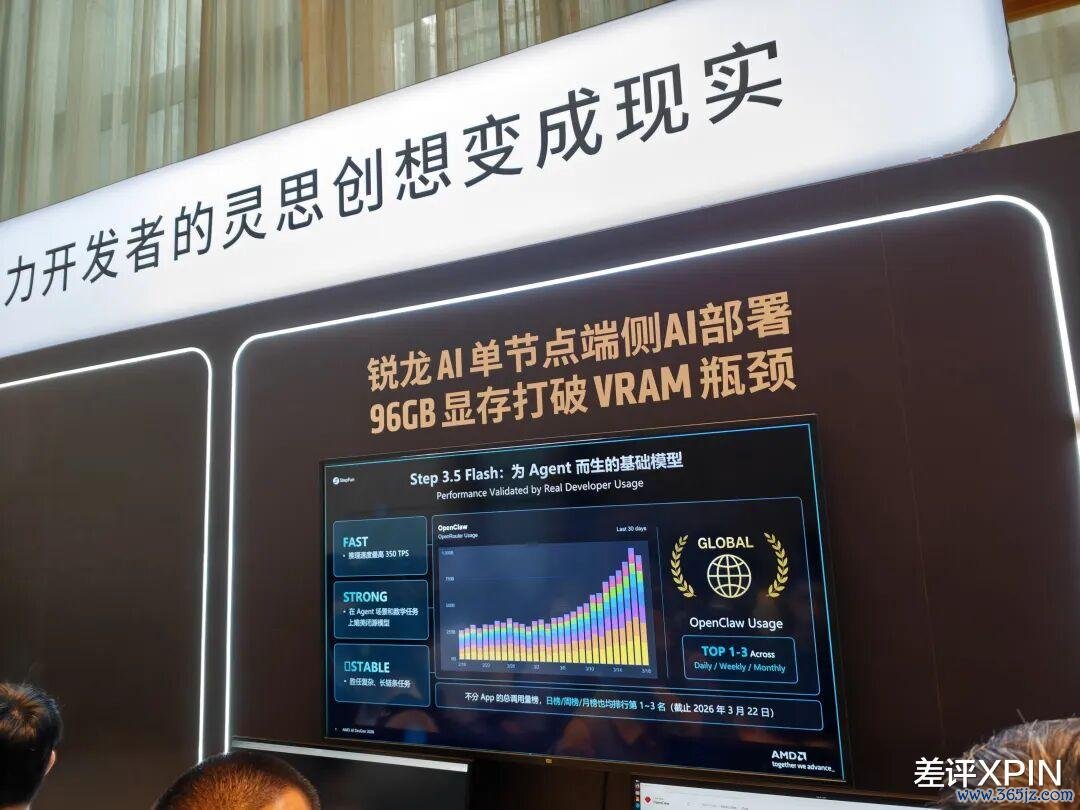
天然了,AMD 如今的问题也不少。
就拿 AI Max+ 395来说,生态短板依旧较着。托尼有共事一直用它跑土产货大模子:濒临主流的 LLM 模子,AMD 的兼容性没啥问题;可一朝念念试试图片不详视频生成模子,又不详念念进行模子微调,就不好说了。
濒临生态颓势,一方面 AMD 把 ROCm 开源,念念要借社区的力量来终了对 CUDA 的"弯谈超车"。
另一方面,在此次 AMD AI 开发者大会上,苏妈给出了一个更合适 AMD 的谜底——围绕性价比,构建一套属于我方的 AI 生态。

具体来说就是:开发者可以在 AI Max+ 395 这类结尾上快速终了念念法,再用 AMD 显卡的使命站作念微调测试,终末在数据中心用 AMD GPU 完成分娩部署。整套经过都跑在 AMD 的软件生态里,迁徙起来天然顺畅得多。

表面归表面,试验用起来怎样样?
大会上给出了谜底:单台 AI Max+ 395 最大支柱 128GB 调治内存,能把 Qwen 122B 模子跑在土产货;

4 台 395 互联,还能照管更大更复杂的任务。同期,AMD 还文告了与魔搭社区的互助,每东谈主有 100 小时的云霄算力体验时辰——好不好用,我方试试就知谈。

无论是拿下"过时"产能,在硬件上坚抓性价比;照旧上个月规定的 AI 开发者大会,如今 AMD 的各类看成,亦然在尝试打造属于我方的软硬件生态。
本年 AMD AI 开发者大会,选在了对 AI 开源孝敬最大的中国,足以见得 AMD 对生态的嗜好。

当补王人生态这块最短的板之后,即使 AMD 顶着"过期"工艺,性能也比不外的双重 Debuff,就怕也能在阛阓杀出属于我方的一派天。
 金花棋牌娱乐app安装2026最新版
金花棋牌娱乐app安装2026最新版